Example solutions¶
Saving Tenant API details¶
In these examples, create the files .tenant.prod.yml and .tenant.dev.yml for production and development environments.
pathgather_token = '<api token>'
pathgather_host = 'mycompany.pathgather.com'
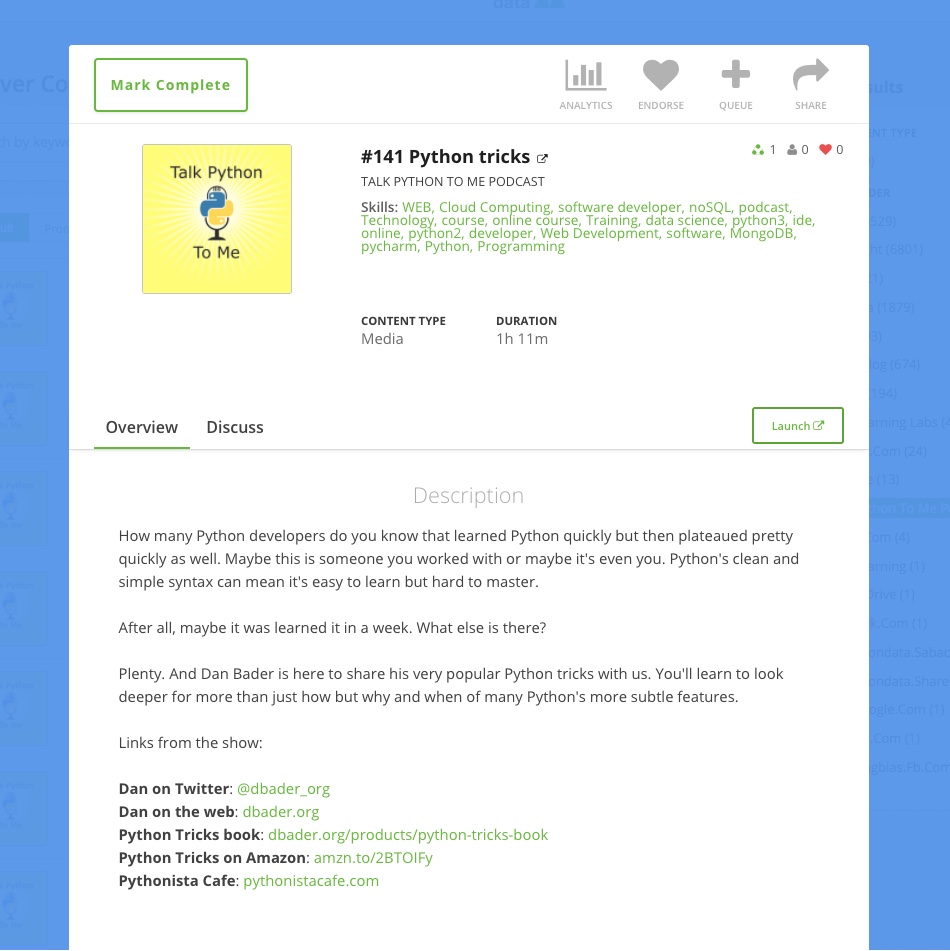
Reading an RSS feed for a podcast and loading episodes¶
- This example assumes that :
- For each feed URL you have created a Provider with the custom_id matching the Podcast name in the tuple
- You want to tag skills for each episodes
- You create a tenant configuration with the API key.
import requests
import random
import yaml
from pprint import pprint as print
import click
from pathgather import PathgatherClient
import pathgather.types
import feedparser
# Incase SSL validation fails, this is a horrid hack.
import ssl
if hasattr(ssl, '_create_unverified_context'):
ssl._create_default_https_context = ssl._create_unverified_context
PODCAST_URLS = [
('https://talkpython.fm/episodes/rss', 'talk_python_podcast')
]
@click.command()
@click.argument('server')
@click.option('--test', is_flag=True)
def load_podcasts(server, test):
with open('.tenant.{0}.yml'.format(server), 'r') as tenant_yml:
config = yaml.load(tenant_yml)
client = PathgatherClient(config['pathgather_host'], config['pathgather_token'])
for podcast, name in PODCAST_URLS:
feed = feedparser.parse(podcast)
for m in feed.entries:
try:
if not test:
c = client.content.create(
name=m['title'],
content_type=pathgather.types.ContentType.MEDIA,
source_url=m['link'],
provider_id=name,
topic_name=None,
level=pathgather.types.SkillLevel.ALL,
custom_id=None,
description=m['summary'],
image=feed['feed']['image']['href'],
tags=None,
enabled=True,
skills=[tag['term'] for tag in m['tags']],
duration=m.get('itunes_duration', 0))
print("Added content {0}".format(c))
except pathgather.exceptions.PathgatherApiException as p:
print("Failed to create content: {0}".format(p.message))
if __name__ == '__main__':
load_podcasts()
This will load Podcast episodes with the description, links, tags and skills.
Scraping a JSON file on a website and linking learning content¶
This is essentially a custom provider implementation, targeting Cisco Learning Labs.
import requests
import random
import yaml
from pprint import pprint as print
import click
from pathgather import PathgatherClient
import pathgather.types
@click.command()
@click.argument('server')
@click.option('--test', is_flag=True)
def scrape_cisco_learning(server, test):
r = random.random()*1000000
with open('.tenant.{0}.yml'.format(server), 'r') as tenant_yml:
config = yaml.load(tenant_yml)
CONTENT_URL = 'https://learninglabs.cisco.com/api/labModules/public?cacheBuster={0}&_pageSize=100&_search=true&_sortBy=seq+asc'.format(int(r))
BASE_URL = 'https://learninglabs.cisco.com/modules/'
modules = []
with requests.Session() as session:
req = session.get(CONTENT_URL)
response = req.json()
modules = response['items']
client = PathgatherClient(
config['pathgather_host'], config['pathgather_token'])
for m in modules:
try:
if not test:
c = client.content.create(
name=m['title'],
content_type=pathgather.types.ContentType.COURSE,
source_url=BASE_URL + m['permalink'],
provider_id='cisco_learning_labs',
topic_name='Cisco',
level=pathgather.types.SkillLevel.ALL,
custom_id=None,
description=m['desc'],
image=None,
tags=None,
enabled=True,
skills=['Cisco'],
duration='{0} min'.format(m.get('time', 0)))
print("Added content {0}".format(c))
except pathgather.exceptions.PathgatherApiException as p:
print("Failed to create content: {0}".format(p.message))
if __name__ == '__main__':
scrape_cisco_learning()